Python+Js 实现超大文件的上传
前言:上传功能现在在各大平台都是显而易见的,我们可以思考一下在网站上传一些小的文件是迅速的,但是为什么上传一下大文件甚至超大文件也是非常迅速的这是怎么实现的呢?这篇文章会告诉你。
在此之前我们需要先了解平常的上传文件流程。
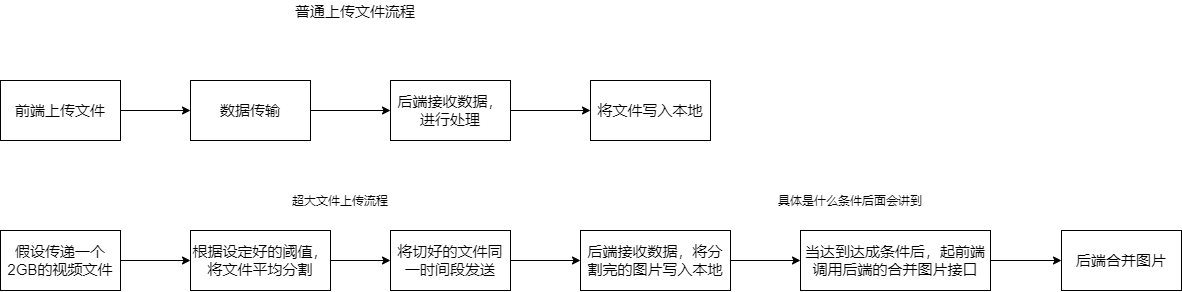
假设我们将阈值设定为500MB(可以把阈值理解为是最小的分割大小),那现在传递一个2GB的文件就会分割为4份文件,但是4份文件我们传递给后端之后顺序是被打乱的,这样的话合并出来的视频就是一张被打乱的视频。所以我们还需要给每个分割开个文件加上一个标识位,可以标示出分割文件的顺序。还有一点重要的就是在什么时机去合并文件(因为有一种情况就是上传图片的途中你的进程结束了,那样你的文件也没有传递完全在这样的情况下我们肯定是不可以去合并文件的)。具体操作请看代码。
话不多说,我们直接上代码
js代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
| <template>
<div >
<p><b>请选择你想要上传的文件:</b></p>
<a-upload
class="upload-list-inline"
:before-upload="beforeUpload"
@change="slice_filess"
>
<a-button>上传文件</a-button>
</a-upload>
</div>
</template>
<script>
import qs from "qs"
export default {
name: '',
data() {
return {
};
},
props: {},
components: {},
created() {
},
mounted() {
},
methods: {
beforeUpload: function (file) {
return false;
},
slice_filess(file){
var filename = file.file.name
var filesize = file.file.size
var shardSize = 1024 * 1024 *2
var shardCount = Math.ceil(filesize/shardSize)
var shardstart = 0
var shardend = 0
var success_count = 0
for (var i=0;i<shardCount;i++){
shardstart = i*shardSize
shardend = Math.min(filesize,shardstart+shardSize)
var slicess = file.file.slice(shardstart,shardend)
let data = new FormData()
data.append("file",slicess)
data.append("index",i)
data.append("filename",filename)
data.append("uid",1)
console.log(">>>>>>>>>>>>>>>>>>>",data)
this.axios.post("/test_shard_upload/",data)
.then(resp=>{
if (resp.data.code == 200){
success_count += 1
if (success_count==shardCount){
this.merge_file(filename,shardCount)
}
}
}).catch(error=>{
console.log(error)
})
}
},
merge_file(filename,shardCount){
this.axios.put("/test_shard_upload/",qs.stringify({'filename':filename,'count':shardCount,"uid":1}))
.then(resp=>{
if (resp.data.code==200){
alert("图片上传成功")
}
}).catch(error=>{
console.log(error)
})
}
},
computed: {},
watch: {},
directives: {},
filters: {}
};
</script>
<style>
</style>
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
| import aiofiles
import shutil
from app.base import BaseHandler
import os
class AdGoodsShard(BaseHandler):
async def post(self):
uid = self.get_argument("uid")
uid = int(uid)
files = self.request.files.get("file")[0]['body']
filename= self.get_argument("filename")
index = self.get_argument("index")
path = f"./static/{uid}_upload/"
if not os.path.exists(path):
os.makedirs(path)
print("图片文件夹》》》》》》》",path)
paths = path+"shard/"
print("切片文件的临时文件夹》》》》》",paths)
if not os.path.exists(paths):
os.makedirs(paths)
async with aiofiles.open(f'{path+"shard/"}{filename}_{index}' , 'wb') as f:
await f.write(files)
return self.finish({'code': 200 , 'msg': "切片上传文件成功"})
async def put (self):
uid = self.get_argument("uid")
ShardCount = self.get_argument("count")
filename = self.get_argument("filename")
path = f"./static/{uid}_upload/shard/"
paths = f"./static/{uid}_upload/"
for i in range(int(ShardCount)):
async with aiofiles.open(f"{path}{filename}_{i}",'rb') as f:
async with aiofiles.open(f"{paths}{filename}",'ab') as f1:
await f1.write(await f.read())
f.close()
shutil.rmtree(paths+"shard/")
return self.finish({'code':200,'msg':'上传图片成功'})
ad_view_urlpatternss = [
(r'/test_shard_upload/',AdGoodsShard)
]
|
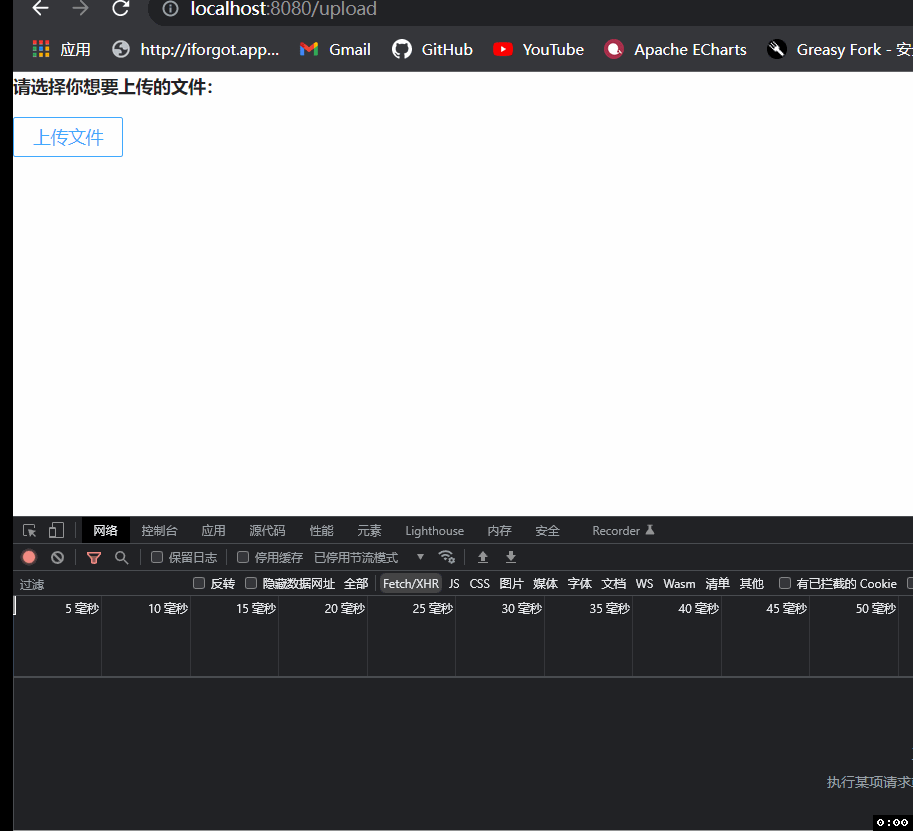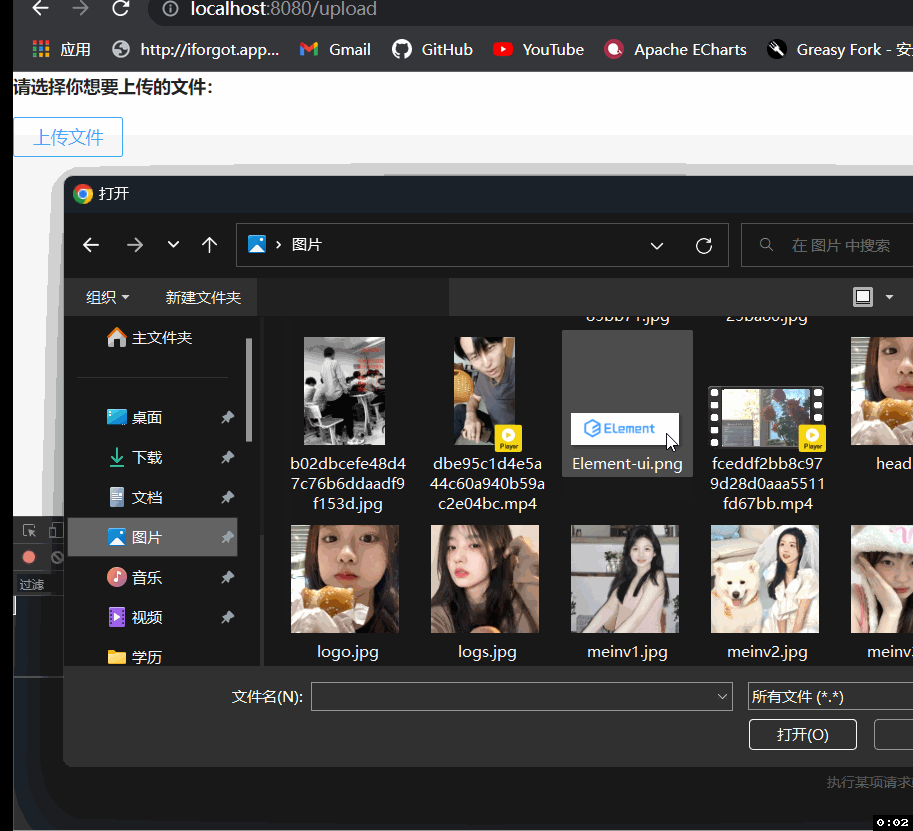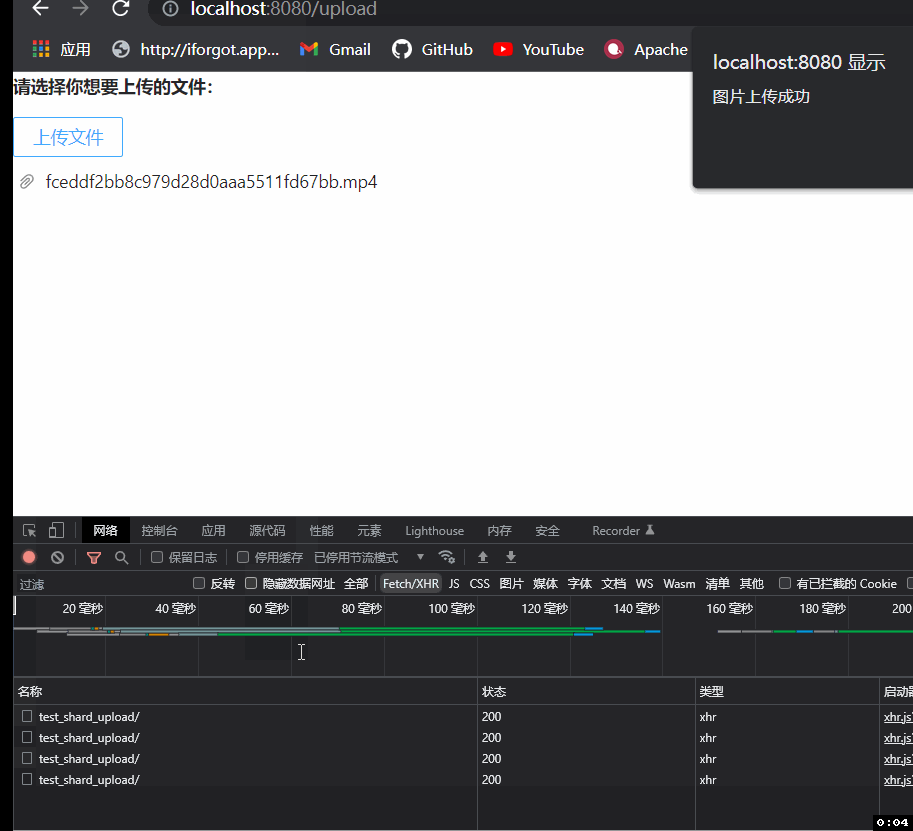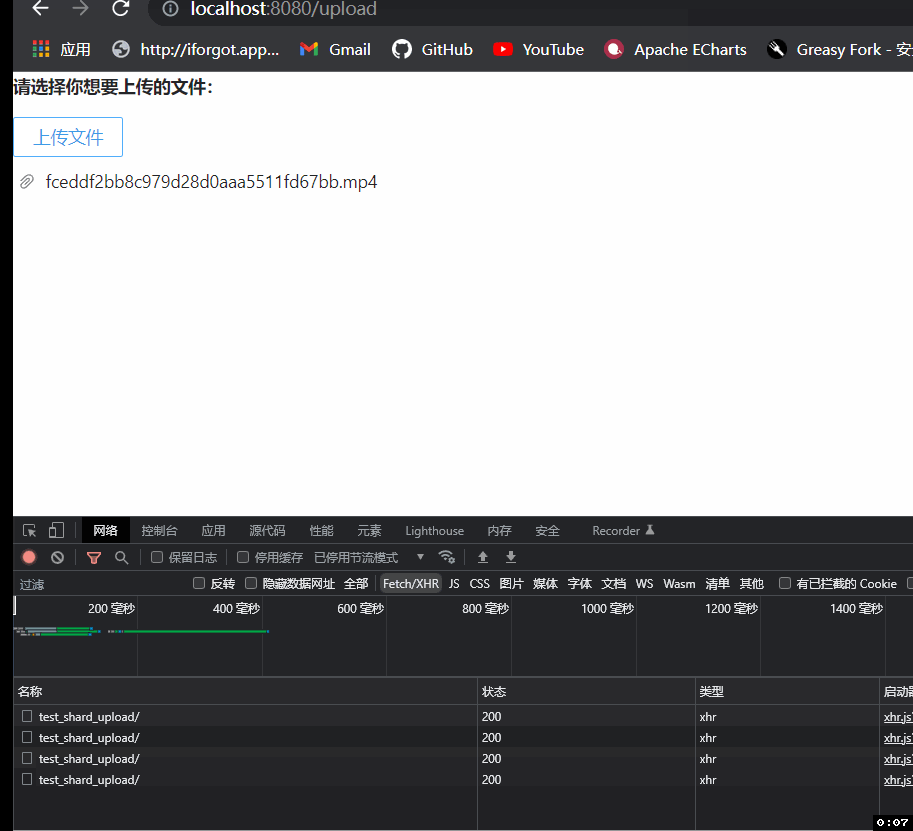
这里我选择一个8.46兆的视频上传测试一下,可以看到视频被切成了3份(因为我们的上传阈值是4兆的,最后不满4兆按4兆传递),只有在前3个请求返回切片上传成功后才调用了第四个合并视频的请求。
结语:以上就是上传文件的大致流程,其实可以看到哪怕七牛云的上传大型文件的底层原理也是切片处理,而切片其中的重点就是切应该怎么切,怎么切可以在合并的时候不导致文件错误,我上面的代码是在Tornado框架+Vue框架里实现的,如果你想要在别的框架使用也是可以的,换汤不换药嘛,只要你理解切片上传的运行原理都可以适用。







